The YOLOv4 architecture can be broken down into several key components: Input, Backbone, Neck, and Head. Here’s a detailed explanation of each part as seen in the provided image:
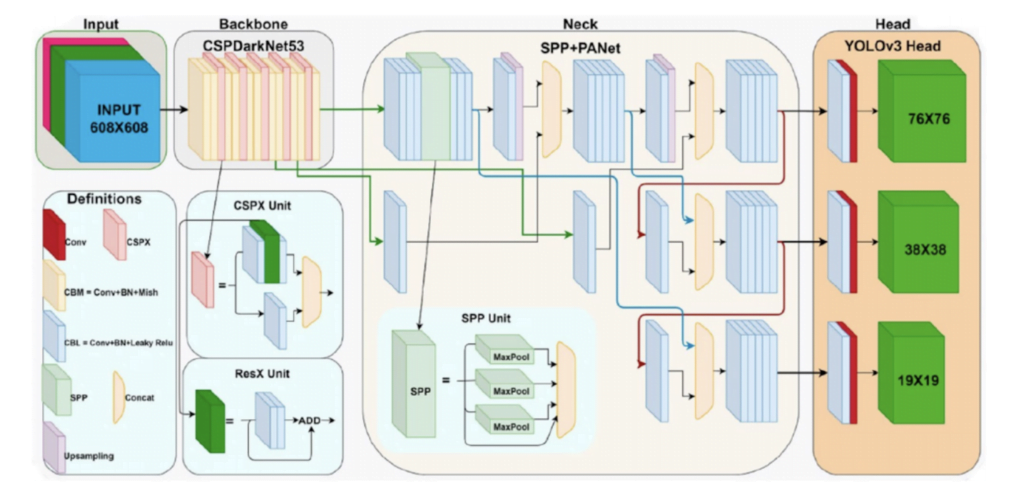
1. Input
- Resolution: The input image is of size 608×608 pixels.
- Preprocessing: The image undergoes standard preprocessing steps to prepare it for the neural network.
2. Backbone: CSPDarknet53
- Initial Layers: The input image is first processed by convolutional layers (Conv) with batch normalization and Mish activation function (CBM).
- CSPX Unit: This unit integrates Cross Stage Partial Network (CSPNet) by dividing the feature map into two parts, processing them separately, and merging them. This helps in reducing computational cost and improving feature extraction efficiency.
- ResX Unit: Residual connections (ResX) are used to facilitate gradient flow and enhance learning by adding the input to the output of convolutional blocks.
3. Neck: SPP + PANet
SPP Unit (Spatial Pyramid Pooling):
- Increasing Receptive Field: SPP pools the feature maps at different scales using various pooling operations (e.g., max-pooling with different kernel sizes). This increases the receptive field without reducing the spatial resolution of the feature maps.
- Multi-Scale Feature Extraction: By pooling at multiple scales, SPP helps the model capture features from different levels of the image, making it better at detecting objects of various sizes.
- Concatenation of Pooled Features: The outputs from different pooling operations are concatenated, providing a richer and more comprehensive feature representation to the subsequent layers.
PANet (Path Aggregation Network):
- Bottom-Up Path Augmentation: PANet enhances the feature pyramid by adding a bottom-up path that complements the top-down path in the feature pyramid networks (FPN). This helps in better information flow between the layers.
- Improved Feature Fusion: PANet ensures that high-level semantic features and low-level positional features are effectively combined. This fusion is critical for precise object localization and classification.
- Enhanced Object Detection: By improving the integration of features across different layers, PANet helps the model detect objects more accurately, especially in complex scenes with varied object sizes and occlusions.
YOLOv4 Head:
The head of YOLOv4 is a crucial component responsible for the final detection of objects. It is designed to operate at multiple scales, ensuring that objects of varying sizes are accurately detected. Here’s a detailed explanation:
Multi-Scale Detection Layers
The YOLOv4 head comprises several detection layers, each responsible for identifying objects at different scales. This multi-scale approach allows the model to handle objects of various sizes more effectively.
- 76×76 Detection Layer
- Role: Detects smaller objects.
- Feature Map Size: The feature map at this scale has a size of 76×76 pixels.
- Advantages: This layer is sensitive to fine details and small objects, which might be missed by layers operating at coarser scales.
- 38×38 Detection Layer
- Role: Detects medium-sized objects.
- Feature Map Size: The feature map at this scale has a size of 38×38 pixels.
- Advantages: It balances between detecting small details and capturing larger context, making it ideal for medium-sized objects.
- 19×19 Detection Layer
- Role: Detects larger objects.
- Feature Map Size: The feature map at this scale has a size of 19×19 pixels.
- Advantages: This layer captures large objects and broader contextual information, which is essential for detecting large objects in the image.
Detection Mechanism
- Bounding Boxes: Each detection layer predicts several bounding boxes per cell. Each bounding box comes with a confidence score and class probabilities.
- Objectness Score: Indicates the likelihood that a bounding box contains an object.
- Class Probabilities: Provide the likelihood of the detected object belonging to a particular class.
To explore the latest advancements in object detection with YOLOv8, click here.